LSNet: See Large, Focus Small
作者:Ao Wang, Hui Chen, Zijia Lin, Jungong Han, Guiguang Ding
论文链接:
论文代码:
发表时间:2025.02.24
摘要:
Vision network designs, including Convolutional Neural Networks and Vision Transformers, have significantly advanced the field of computer vision. Yet, their complex computations pose challenges for practical deployments, particularly in real-time applications. To tackle this issue, researchers have explored various lightweight and efficient network designs. However, existing lightweight models predominantly leverage self-attention mechanisms and convolutions for token mixing. This dependence brings limitations in effectiveness and efficiency in the perception and aggregation processes of lightweight networks, hindering the balance between performance and efficiency under limited computational budgets. In this paper, we draw inspiration from the dynamic heteroscale vision ability inherent in the efficient human vision system and propose a ``See Large, Focus Small'' strategy for lightweight vision network design. We introduce LS (\textbf{L}arge-\textbf{S}mall) convolution, which combines large-kernel perception and small-kernel aggregation. It can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information. Based on LS convolution, we present LSNet, a new family of lightweight models. Extensive experiments demonstrate that LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks. Codes and models are available at this https URL.
1. 简介
SAR视觉定位(SARVG)——暂未完成
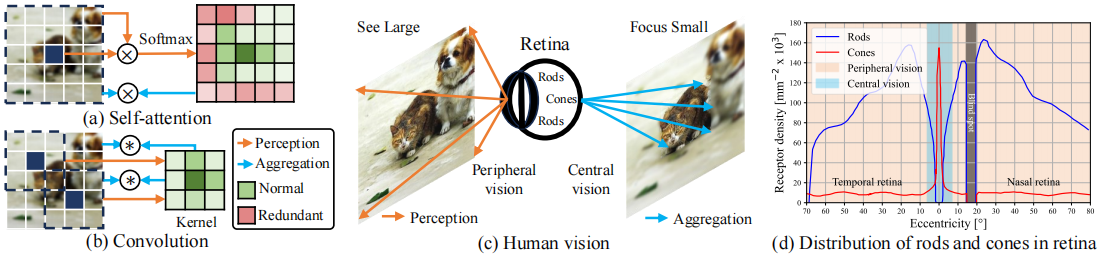
Fig. 1. (a) 自注意力(Self-Attention)和 (b) 卷积(Convolution)的机制。(c) 表明人类视觉系统可以通过周边视觉“看大”,通过中心视觉“聚焦小”。(d)显示视杆细胞和视锥细胞的分布取决于人眼中央凹的偏心率。它们有助于形成广泛的周边视觉和焦点中央视觉。
2. 创新
提出LS(Large-Small)卷积,结合大核感知(Large-Kernel Perception,LKP)和小核聚合(Small-Kernel Aggregation,SKA)能力。
提出LSNet(Large-Small Network)轻量级模型系列,引入LS卷积和深度可分离卷积和分组机制。
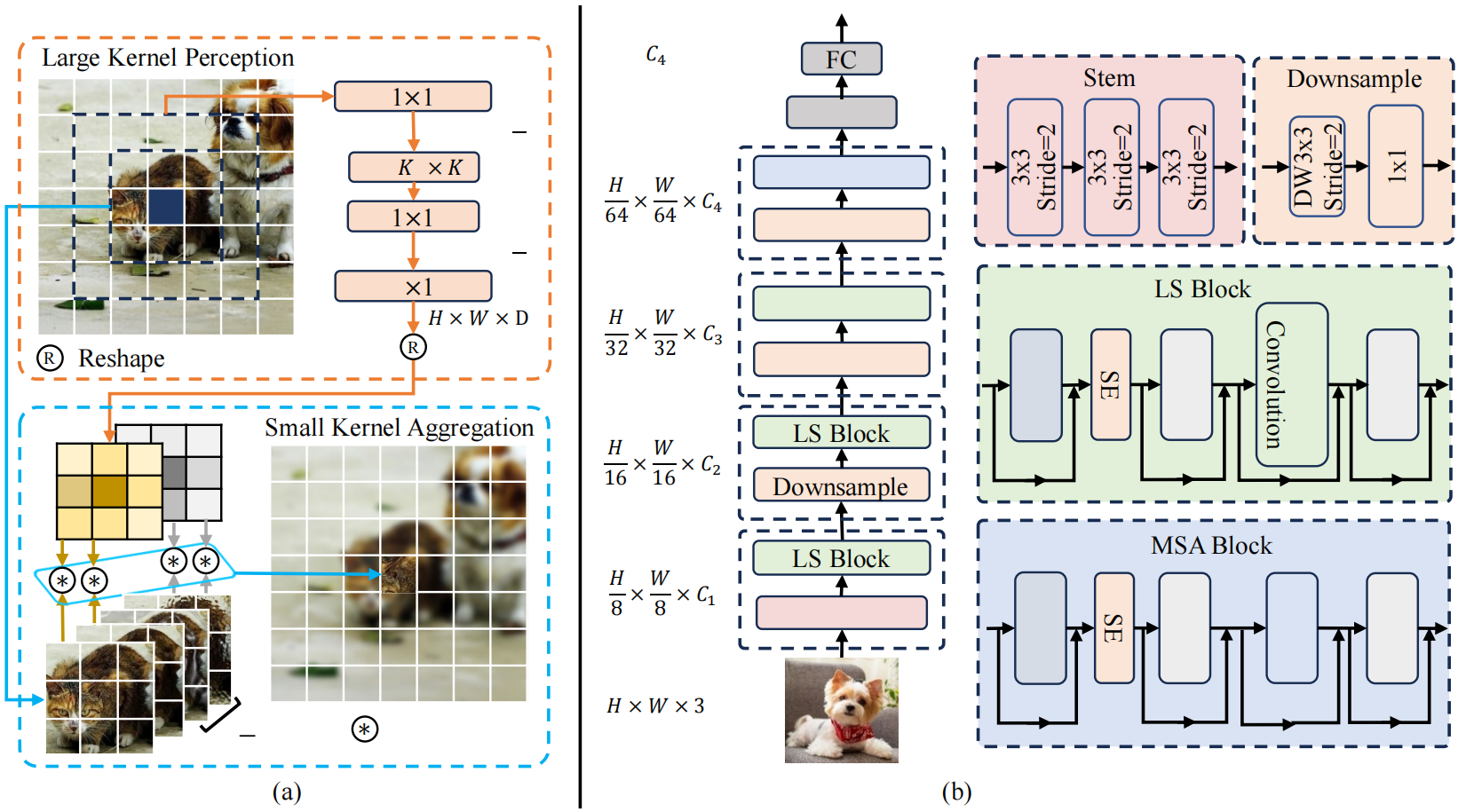
Fig. 3. (a) LS卷积,包括大核感知(上)和小核聚合(下)。(b) LSNet,包括4个阶段(分辨率分别为 \frac{H}{8} \times \frac{H}{8}、\frac{H}{16} \times \frac{H}{16}、\frac{H}{32} \times \frac{H}{32} 和 \frac{H}{64} \times \frac{H}{64}),图中省略了Norm层和非线性层。
3. 方法
3.1 对比
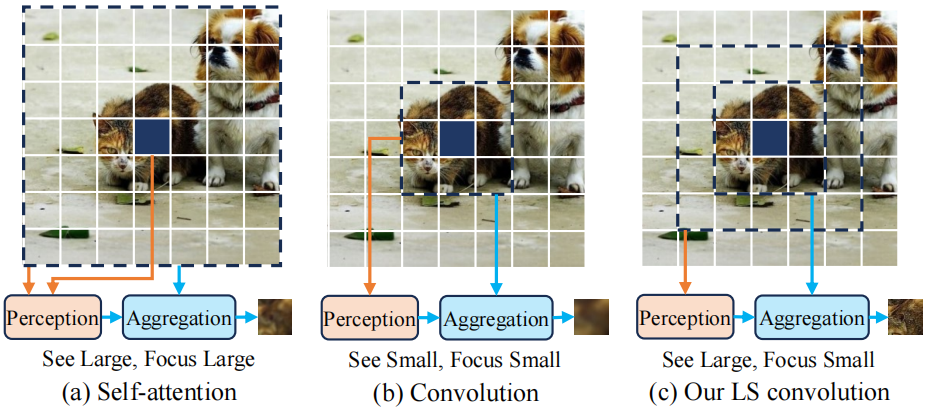
Fig. 2. 自注意力、卷积和提出的LS卷积间的对比。
3.2 LS卷积
3.2.1 问题
自注意力在信息量较少的区域进行冗余注意和过度聚合,限制轻量级模型的效率。且对 x 进行的操作尺度一致,导致增加Token混合范围时计算复杂度显著增大。
卷积的Token混合范围由卷积核大小决定,但在轻量化模型上通常过小,导致感知范围小。而由感知建模的Token间关系(聚合权重)只取决于相对位置,且由所有Token共享并固定,而难以适应其相关的上下文。
3.2.2 公式
y_i=\mathcal{A}(\mathcal{P}(x_i,\mathcal{N}_P(x_i)),\mathcal{N}_A(x_i))。
其中,x_i \in \mathbb{R}^C是Token, \mathcal{N}_P(x_i) 和 \mathcal{N}_A(x_i) 分别表示感知和聚合的上下文区域(前者比后者空间范围大)。
3.2.3 流程
对较大范围的 \mathcal{N}_P(x_i) 进行感知,捕捉整体的上下文信息 \mathcal{P}=\mathcal{P}(x_i,\mathcal{N}_P(x_i)),如采用大核深度卷积(Large-Kernel Depth-Wise Convolution,DW),以最小的代价扩大感知范围。
对较小范围的 \mathcal{N}_A(x_i) 进行聚合,捕捉细粒度细节 \mathcal{A}(\mathcal{P},\mathcal{N}_A(x_i)),可采用自适应特征加权求和,保证低计算成本,减少不重要的注意力聚合。
3.2.4 大核感知
3.2.4.1 公式
3.2.4.2 流程
\mathcal{N}_{K_L}(x_i) 为以 x_i 为中心、 K_L \times K_L 为大小的空间范围。
使用逐点卷积(Point-Wise Convolution,PW)将Token投影至低维,默认为 \frac{C}{2},即 \rm{PW}(\cal{N}_{K_L}(x_i))。
使用 K_L \times K_L 的大核深度卷积高效捕获 \mathcal{N}_{K_L}(x_i) 的大范围空间上下文信息。
使用PW对Token的空间关系进行建模,生成上下文自适应的聚合权重 W \in \mathbb{R}^{H \times W \times D}。
3.2.5 小核聚合
3.2.5.1 公式
3.2.5.2 流程
X \in \mathbb{R}^{H \times W \times C} 是视觉特征图,\mathcal{N}_{K_S}(x_i) 为以 x_i 为中心、 K_S \times K_S 为大小的空间范围。
将 X 的通道分为 G=\frac{G}{C} 组,同一组共享聚合权重。
将每个 \omega_i reshape为 \omega^*_i \in \mathbb{R}^{G \times K_S \times K_S},K_S \times K_S 为小核大小。
使用 \omega^*_i 聚合 \mathcal{N}_{K_S}(x_i) 的高相关区域。
定义 x_i 的第c通道为 x_{ic},属于第g组。
对 \omega^*_{ig} \in \mathbb{R}^{K_S \times K_S} 和 \mathcal{N}_{K_S}(x_{ic}) 进行卷积,获得 x_{ic} 的聚合特征表示 y_{ic}。
3.3 LSNet
3.3.1 变种
K_L=7,K_S=3,G=\frac{C}{8}。
3.3.2 LS Block
在最初的3个阶段各使用1次LS Block。
使用LS卷积进行Token混合。
使用跳跃连接(Skip Connection)便于模型优化。
使用额外的DW和SE 层引入更多局部归纳偏差,增强模型能力。
使用前馈网络(Feed Forward Network,FFN)进行通道混合。
3.3.3 Overlapping Patch Embedding
采用3次 3 \times 3,S=2 卷积,将图像投影为视觉特征图,代替Patch Embedding。
3.3.4 下采样
采用 3 \times 3,S=2 DW和 1 \times 1 PW分别降低空间分辨率并调整通道数。
3.3.5 MSA
在最后一个阶段使用1次,用于捕捉低分辨下的长距离依赖(参考MobileViT和FastViT)。
结合多头自注意力(Multi-Head Self-Attention,MHSA)。
使用DW和SE 层引入更多局部结构信息。